When I began working in a university, part of my job was supporting a group who used LaTeX. They used Unix systems, and I maintained LaTeX on them. Installing could sometimes be a slog - fonts were a hassle, and packages kept appearing and re-appearing with inter-dependencies. I produced some handouts to help people with LaTeX. LaTeX2e appeared, which helped.
Time passed. The web was invented, so I put the handouts online, first as postscript docs, then PDF, then HTML/MathML. A web search for Tim Love LaTeX reveals that those docs have been widely copied. Documents like The Not So Short Introduction to LaTeX2e by Tobias Oetiker et al, LaTeX for Complete Novices by Nicola L.C. Talbot and Using Imported Graphics in LaTeX and pdfLaTeX by Keith Reckdahl have taken away the need for books, though the TeX Book is still useful.
As Word improved, LaTeX use seemed to recede, recovering as Linux appeared, LaTeX distributions became more stable, and cross-platform front ends like Kile and Texmaker were developed. pdfLaTeX became the predominant latex processor, DVI files becoming a rarity. As web pages grew in sophistication, LaTeX->HTML convertors became less fashionable (I used to generate PDF and HTML files from LaTeX masters, but tend to maintain the files separately now). The LaTeX page in our help system grew. I started giving talks on LaTeX for beginners and for report writers. Some staff made their undergraduate students learn LaTeX.
The CTAN sites became more comprehensive. A searchable catalogue appeared. Usenet newsgroups became Web forums, and sites like latex-community and tex-latex stackexchange attracted beginners and experts.
The LaTeX community has always been mutually-supportive and widely dispersed. Local support is much less necessary than it used to be, but sometimes it helps provide continuity. A Ph.D student who'd been to my talks and had read my handouts produced a class to support local thesis writers and left it with me when he left. It proved popular - our 3rd most popular help-system page. Another student who'd been to a talk improved the class in 2013 - it's available via our help system.
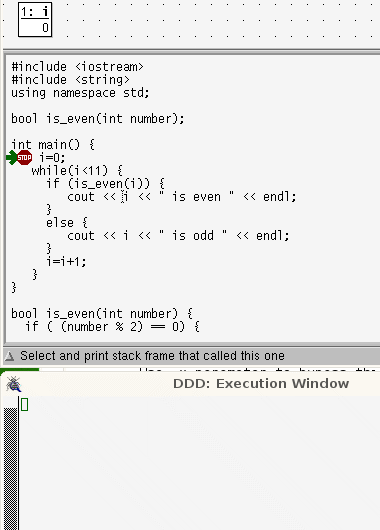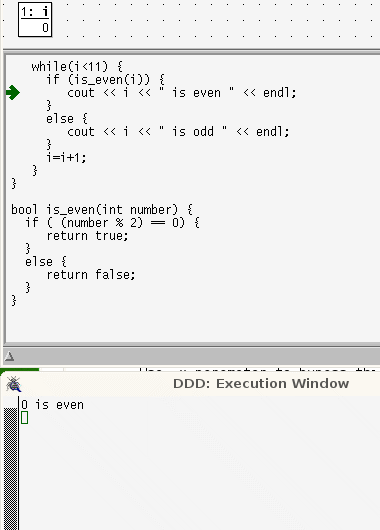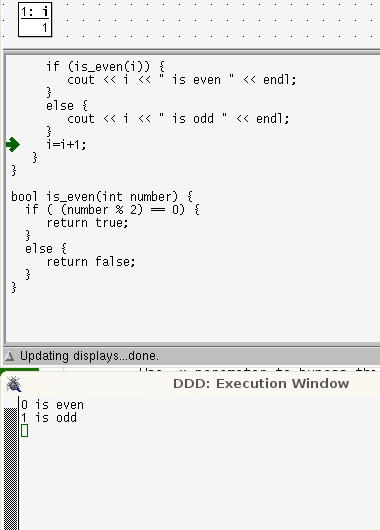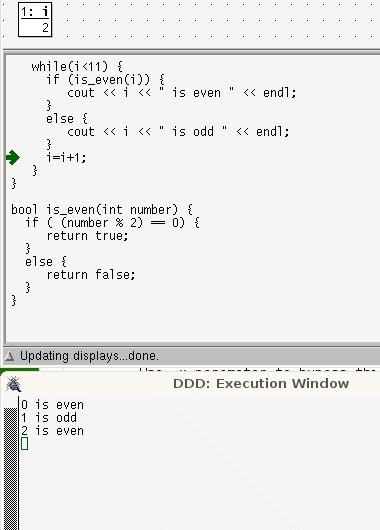
 while loops are more linear than for loops. In a while loop the lines that are repeatedly run are contiguous and in order; control takes only one step back.
while loops are more linear than for loops. In a while loop the lines that are repeatedly run are contiguous and in order; control takes only one step back. In a for loop, the locus of control passes through the terminating condition, the body of the code, then back to the last statement, then back again, to the terminating condition before executing the body code again
In a for loop, the locus of control passes through the terminating condition, the body of the code, then back to the last statement, then back again, to the terminating condition before executing the body code again